Our world is truly becoming IoT-powered — even the simplest appliances like a fridge or air conditioner nowadays leverage a combination of various IoT modules and custom IoT software to interact with physical and digital worlds.
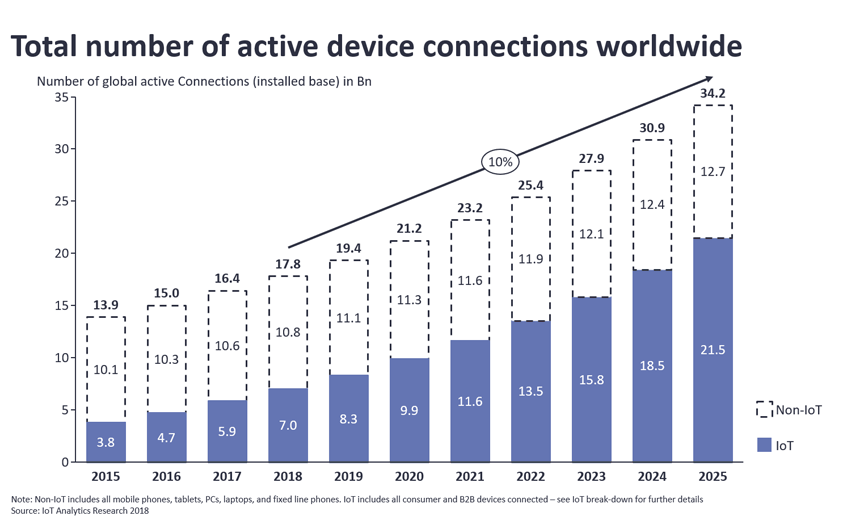
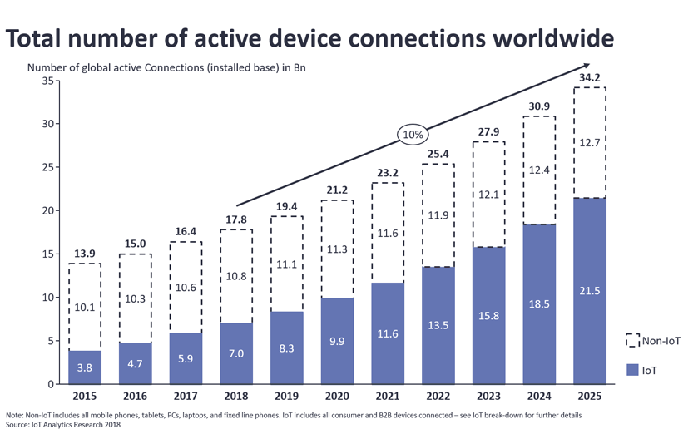
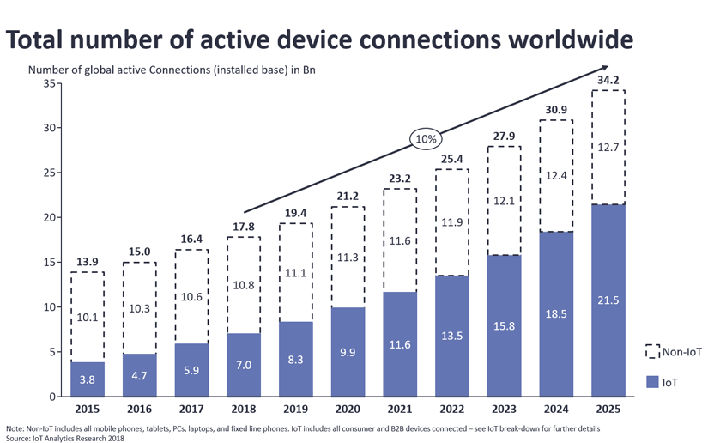
According to IoT Analytics Research 2018, the number of connected devices exceeded 17,5 bln earlier this year and Cisco forecasts this number to grow up to 50 bln devices by 2020 — that’s more than 6 IoT devices per each person on Earth.
All these devices minutely generate thousands of terabytes of valuable data — how many calories a day we burn, what room temperature we prefer, which medicines help us better, how many cars a day goes through this crossroads, and more.
But the majority of the companies, even IoT-minded ones, treat the data from smart devices ineffectively — according to Harvard Business Review, over 99% of unstructured data gets lost.
Let’s have a glance at 4 common mistakes which prevent companies from striking gold with IoT big data analytics.
Collecting Excessive Data
What’s the mistake?
According to EMC research, the amount of IoT data is growing exponentially and by 2020 its volume would be equal to 6.6 stacks of fully-loaded 128gb iPads spreading from Earth to the Moon.
Companies who are new to IoT sometimes operate under a misconception that the more data you extract, the better.
As a result, their storage is swelling with terabytes of both structured and unstructured data, dozens of analytical tools are working up a sweat, but companies still see no significant business value. There is a reason for that — not all of data is equally insightful for one particular business.
How to avoid it
To make sure that the data works properly and really improves your business, you need to work out an IoT big data business strategy and a clear roadmap. It will help you to select the right IoT sources and focus your resources on only on the most relevant data.
It’s also possible that you already have a functional data system you don’t want to uproot. In this case, try to implement edge computing for intelligent data pre-processing.
Edge computing enables on-device processing for the major part of generated data — you don’t have to constantly send it to the cloud and depend on Internet bandwidth. Let the edge computing first sort out all the potentially valuable data and only then push it upstream for analysis — that’s one way to dramatically increase the insights’ quality without affecting the solution’s costs.
Not Paying Enough Attention to Unstructured Data
What’s the mistake?
According to the researchers from Merrill Lynch, Gartner and IBM, around 95% of data generated by companies daily is unstructured, and if we talk about IoT big data, this number exceeds 99%. IoT data proves to be most insightful for business purposes, but at the same time, it’s very difficult to process because traditional analytical tools will have a hard time interpreting and making sense of heterogeneous data.
Just imagine: your IoT devices extract tons of precious information from the physical world — sensor readings, audio, video, images, social feedback, and more — but less than 1% of it brings value to your business.
How to avoid it
Implementing machine learning algorithms and cognitive computing seems to be the perfect solution for effective handling of unstructured IoT big data.
Data mining, pattern recognition, natural language processing, computer vision — unlike traditional tools, these techs can normalize and process all types of unstructured data, aggregate it, and transform into actionable insights in an automated or semi-automated manner.
Building the entire IoT data analytics system on premises is not always the most effective way of doing things — it demands a lot of time, resources and expertise to design and maintain a functional platform for unstructured data analysis.
However, there are a number of easy-to-integrate yet powerful open source frameworks and IoT big data platforms to arm you with the data processing and analytics capabilities. Consider integrating your Internet of Things ecosystem with the IBM Watson IoT platform or Google Cloud Dataproc — these comprehensive systems provide you with capabilities to pre-process raw device data of any nature (text, image, video, audio, sensor readings), deeply analyze it in real-time, and present the results via visually-rich, informative monitors and dashboards.
Streaming All IoT Data Into the Cloud
What’s the mistake?
Today a lot of companies have fleets of various IoT devices, deeply integrated into the business processes. These devices continuously generate hundreds of data streams and direct them to the cloud without thinking twice — for normalization, aggregation, and analysis. Leveraging virtually unlimited computational resources of the cloud seems to be the most effective way of treating huge pools of IoT data — but it also has a few significant drawbacks:
- IoT devices usually collect lots of your client’s personal information like financial details, medical history or GPS data. By sending sensitive raw data to the cloud you constantly expose it to the risks of breaching.
- When delegating all your IoT data analytics to the cloud-based ML algorithms for real-time data analysis, you become heavily dependent on the quality of internet connection and low latency.
How to avoid it
Try to decentralize your IoT data analytics through the implementation of edge analytics, fog computing, and cloudlets. The common idea of these approaches is to build a more distributed and effective computation ecosystem — edge IoT devices, small-scale cloud datacenters, and fully-fledged upstream analytics platforms are all to be involved into data processing.
The raw device-generated data is first normalized and pre-processed on-device and then only the most relevant and promising data is sent to the cloud platforms for final analysis and insights extraction. This approach helps to solve both problems of data security and dependence on connection quality.
The majority of the data never leaves the client’s device, and if you need to send the data to the cloud for a full-swing analysis, it will be pre-processed, anonymized and privacy compliant, which significantly decreases the risk of breaching in transit and improves data integrity.
Moreover, poor network coverage or limited bandwidth cannot affect the productivity of your real-time analytics — your Internet of Things devices don’t have to keep a connection with a cloud platform every second, all they need is a periodic sync.
There are a number of edge computing solutions to integrate with your endpoint and gateway devices quickly and seamlessly, without redesigning the whole IoT architecture. Consider marrying your system with IBM Watson Edge Analytics or Apache Edgent, which are powerful platforms to introduce edge computing on your project.
However, these tools cannot do magic and address all the project challenges in a snap — they need a heavy purpose-driven customization to unleash the full potential of edge computing. Make sure that you have enough expertise to minutely configure these products and smoothly integrate them into your IoT ecosystem without compromising its overall effectivity.
Some business projects offer unique data challenges — trying to solve them with out-of-the-box solutions sometimes would be quite expensive or even impossible. Crafting a custom edge analytics solution may be a perfect option for the case — you’d be able to create a highly-performing and cost-effective solution by designing the optimized IoT architecture, synchronizing solution’s functionality with the specific project goals, and adjusting data processing flows to a T.
Analyzing IoT Big Data Retrospectively, Not Proactively
What’s the mistake?
The majority of IoT data is sensor-generated and highly time-sensitive, which means the more you wait until processing such data — the less real value you can extract from it.
If acting slowly on your IoT big data, you’re losing the ability to get immediate data-driven insights and automatically trigger some actions or events. A system continuously analyzing sensor readings from the wearable cardiac monitor may save a person’s life by sending an emergency request to the hospital on observing abnormal activity. Or how about self-driving cars — they require such an extreme level of responsiveness to the road situation that its software has to constantly aggregate and analyze data flows from onboard sensors, cameras, and other sources.
Retrospective analysis, on the other hand, may be an effective way to get insights from some types of data — for example, statistics of population growth — but it’s almost never applicable to dynamic data from smart devices.
However, some companies are still failing to maximize the value of collected data by postponing its analysis and merely aggregating it in huge stagnant databases.
How to avoid it
Real-time processing vitalizes big data generated by IoT devices — companies can fully leverage the data the second it leaves the device to make proactive business decisions and gain a huge competitive advantage.
But readjusting your solution from retrospective batch processing to working with data streams requires an integrated system of powerful ETL engines, real-time analytics frameworks, and huge computational resources.
There are few major platforms that combine all these features under one roof and you may consider integrating with one of them to harness an advanced IoT data streaming analytics.
For a start, have a closer look at Elastic Stack (Elasticsearch, Kibana, Logstash), SAP Hana or Apache Services — Kafka, Storm, and Spark. They offer synchronized data ingestion from multiple data sources, on-the-fly data analytics, effective storing of real-time data in operational databases, and more.
Synergizing Innovative IoT Approaches to Beat the Competition
In a nutshell, building an effective IoT data system is not about collecting all the data you can, but carefully selecting what data is really valuable for you, what tools do you need to tame it and what people you need to address business goals most effectively.
Take advantage of the cutting-edge architectural approaches like edge computing, fogging, and cloudlets, explore the capabilities of integrated IoT platforms from IBM, Apache or SAP, and carefully handpick a team of top-notch IoT engineers to customize those solutions in accordance with the specifics of your business project.
Leverage our team of engineers, solution architects, and data scientists to benefit from our years of expertise across the IoT and big data domains.
Whether you need to work out a clear IoT big data strategy, optimize your smart device infrastructure, redesign an existing big data system, or build a custom analytics solution — we’re here to help.