












This website uses cookies to help improve your user experience




— Geoffrey Moore
Becoming a data-driven enterprise is certainly a winning strategy, while a data warehouse is the driving power for informed strategic decisions based on predictive analytics and meaningful reporting solutions. Should we keep data in-house or outsource it to a hosting provider? Which infrastructures are viable for our business: on-premises or cloud-based? How to build a data warehouse from scratch? These are the major questions customers address to Oxagile’s data engineers.

We highlighted customers’ concerns about data warehouses (DWH) during a Q&A session with Alena Gabaraeva, Data Engineer at Oxagile. She shed light on what makes up a data warehouse architecture and how a typical data warehouse implementation plan may look.
Key takeaways:
A data warehouse is a centralized system where a company stores and analyzes information from multiple data sources. You collect data from operational systems such as CRM, ERP, product databases, or external platforms and load it into one analytical environment.
Operational databases record daily activity. Each purchase, login, or support request enters the system as a transaction. These systems focus on speed and reliability.
A data warehouse serves a different goal. Teams analyze data across months or years. Analysts run complex queries, build reports, and identify trends.
For example, a streaming platform may analyze several years of viewing data to see which genres perform best in different regions or seasons. Analysts then track audience behavior, content engagement, and subscription trends using one dataset.
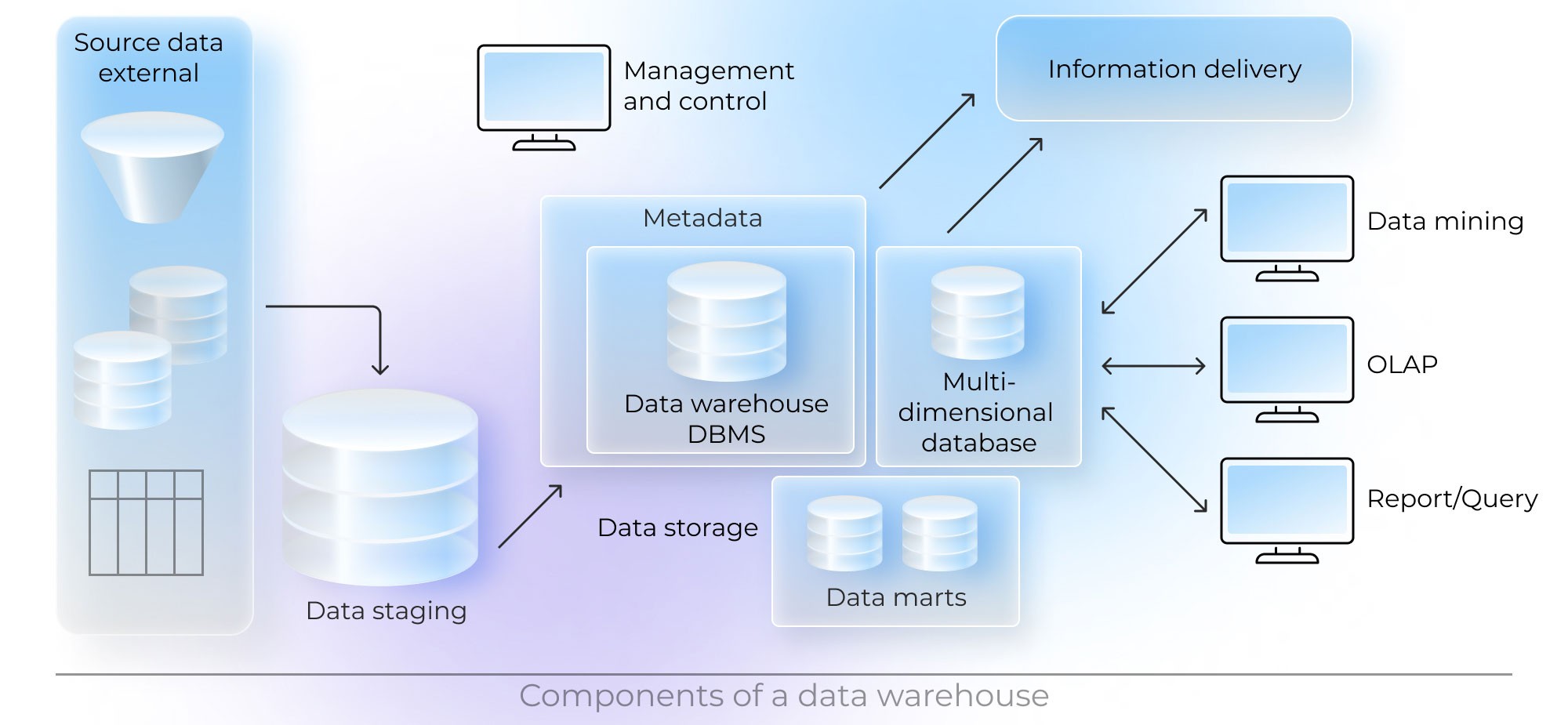
If you want to understand how to implement data warehouse infrastructure, you need to plan architecture, data integration pipelines, and analytics tools from the start. The key system components include:
Companies across industries rely on centralized data platforms to support analytics and decision-making. A well-designed data warehouse brings business data into one environment and makes it easier to analyze, report, and share insights across teams.
Some of the advantages of implementing data warehouse solutions include the following:
Messy pipelines and fragmented sources slow everything down. Our data engineers build scalable architectures that keep your data flowing smoothly.
Before you start implementation, you need to estimate the scope and cost of the system. The architecture, data volume, and number of integrations affect total investment.
The cost of a data warehouse grows as your data environment expands. A small setup may collect data from a few systems and support reporting for one team. At enterprise scale, the platform processes large volumes of data and supports analytics across many departments like product, marketing, and leadership.
Data engineering teams often group projects into three levels.
Let’s explore how these implementation levels differ across key cost drivers.
Cost driver | Entry-level implementation | Department-level platform | Enterprise-scale platform |
Data volume and growth | GB-few TB of mostly historical data; slow growth | Multi-TB datasets with steady growth | Large-scale data (tens/hundreds of TB or PB) with continuous expansion |
Infrastructure and compute resources | Single cloud warehouse or small database instance | Scalable cloud infrastructure with multiple compute clusters | Distributed architecture with high compute elasticity and large storage layers |
Data integration complexity | Few structured sources with simple ETL pipelines | Multiple internal and external systems with transformation workflows | Many heterogeneous sources (APIs, IoT, apps) with complex orchestration pipelines |
Engineering workforce | Small implementation team (1-3 specialists) | Cross-functional team including data engineers and BI developers | Large team including data engineers, architects, ML engineers, and DevOps specialists |
Performance and availability requirements | Periodic reporting with relaxed latency requirements | Near–real-time dashboards and moderate concurrency | High-concurrency analytics, real-time processing, and strict uptime requirements |
Governance, security and compliance | Basic access control and manual monitoring | Automated data quality checks and governance policies | Enterprise-grade governance, auditing, compliance frameworks, and automated monitoring |
“A data warehouse architecture includes technological elements that can be adjusted to the specific needs of an organization. Still, the core of the architecture is made up of the components below:
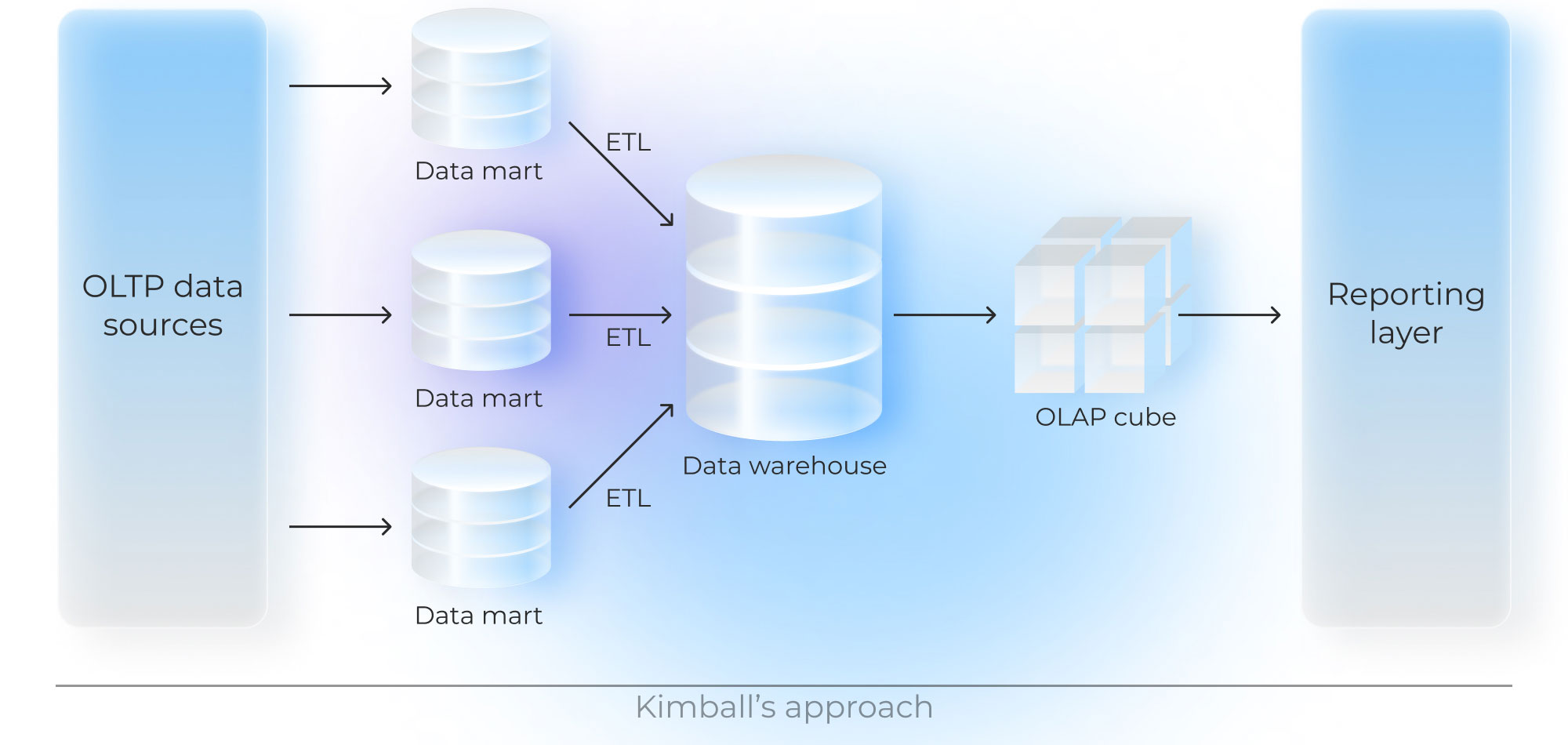
There are two traditional design methodologies used to build a data warehouse architecture: Inmon’s approach and Kimball’s approach. When applying the former, data architects design a centralized storage first and then create data marts from the summarized data warehouse and metadata. The latter follows the opposite process: initial creating of data marts and then the development of a data warehouse database from independent data marts.
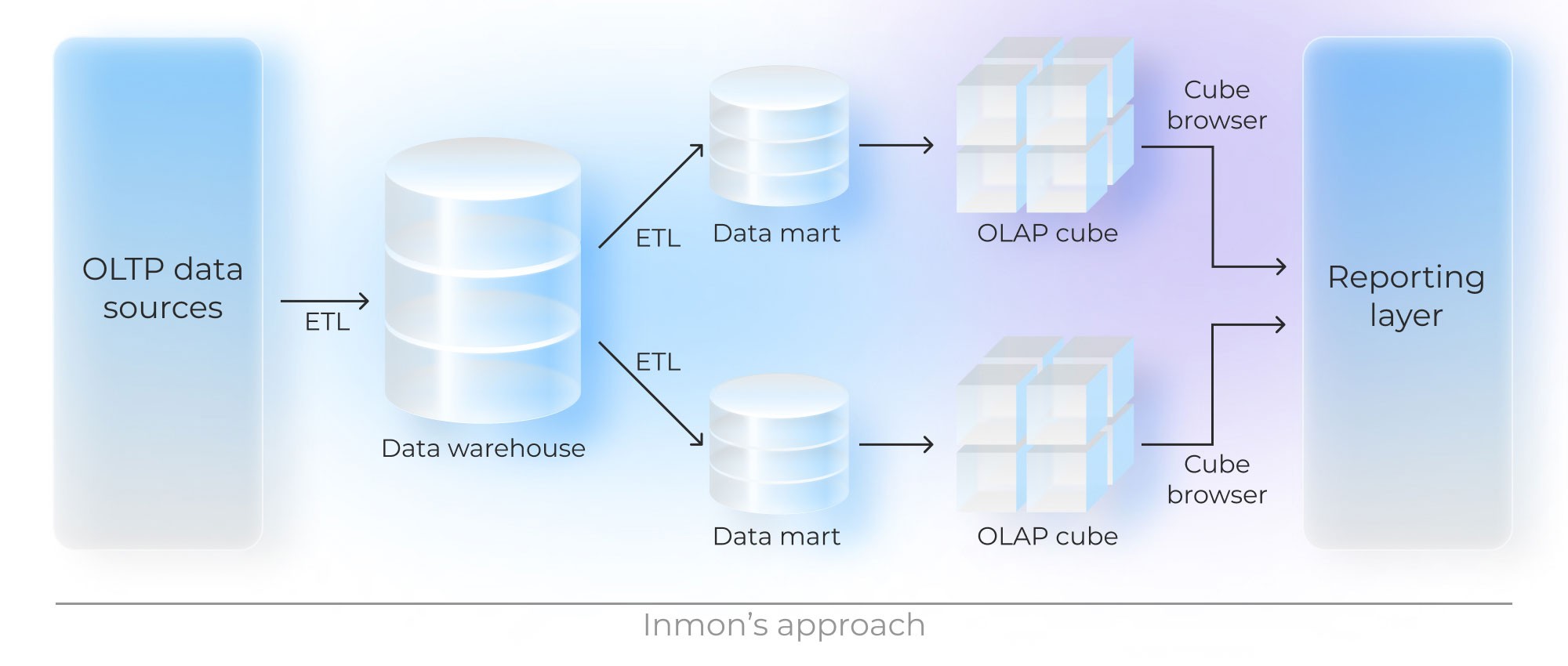
“Both methods work for business, but the market instability makes businesses adapt by being agile. That’s why a new methodology, Data Vault modeling, is gaining popularity due to its agility principles.
The methodology improves DWH flexibility and scalability by allowing refactoring and reuse of familiar architectures for future use cases within the company. Finally, the main advantage of this approach is a faster time-to-market, which may be critical for specific business domains: those who can respond to changes instantly stay competitive. That’s a fact.”
Every business case is all about specific needs, so you can’t just apply the same steps to each project. While talking to our expert, we dived into the flashbacks from the project she was deeply involved in to clearly understand each step of a data warehouse implementation plan.
Let us briefly tell you the context of the story. It’s quite a common case for businesses storing data in multiple sources. To subscribe the existing reporting to a centralized data warehouse system, such companies have to integrate all the data into the new DWH.
How does it typically work? A common warehouse implementation project includes such steps as:
The very first factor to decide on is the availability of data warehouse deployment options. That’s why be sure you explore the data storage restrictions within the local jurisdiction. Let’s say your business is in the USA; in this case, you must consult on the laws at the state level as there is no single principal data protection legislation. It may occur that you would be limited to keeping data servers located physically within the state (country) of your jurisdiction, so on-premises deployment will be the only possible option.
What if you’re given a free hand to choose among cloud-based and on-premises infrastructures? It’s worth analyzing both options’ pros and cons related to finance and maintenance. For instance, cloud server providers commit to maintaining all hardware and fixing data processing issues, but it may take time. For some organizations, the inability to tackle the issue on site as soon as possible might be critical. However, hosting corporate servers requires an in-house IT department to tackle all the issues on their own, which may be costly enough for small and medium-sized businesses.
“When working on the DWH implementation for an eCommerce company, we analyzed their business specifics and country laws related to data storage and processing. Since the company’s target clients and location were within the same jurisdiction, that didn’t allow keeping data logs on servers located outside that country, so we had to establish an on-premises infrastructure.”
Measure data use and understand its complexity Hardware-related things are done; it’s time to choose an appropriate software stack. Data analysis is a must-have preparation step for the data warehouse implementation project. To correlate the vendor’s DWH software with the potential costs, you need to analyze the answers to the questions, “What’s the amount of data aggregated by the business, and what’s the growth potential?”, “What’s the data that needs processing, and where does it come from?”
“As I’ve mentioned above, we couldn’t deploy the data warehouse in the cloud, so after analyzing client data, we chose Oracle and Cloudera. Still, the final determinant was cost-effectiveness, which brought a victory to Cloudera. It allowed us not only to save costs but also handle multiple data integrations and scale the DWH infrastructure smoothly, making the implementation easier.”

A data warehouse architecture serves the foundation for its implementation. In addition to an in-depth analysis of data sources, data architects cover the processes below to design the data warehouse architecture:
“At this stage, data analysts and data architects worked in tandem: the former analyzed the sources and mapped data objects, while the latter designed them for the data staging and other components. By designing the architecture, they provided the data warehouse with high-quality aggregated data and identified source-to-target data flow scenarios.”
Finally, it’s time for production. The key processes covered at this stage include:

See how an OTT platform leveraged big data analytics to monitor infrastructure performance, analyze viewing patterns, and improve content monetization. The solution aggregates statistics from distributed sources to support smarter operational and business decisions.
Key results:
So, is the data warehouse the future for data-driven businesses?
Alena notes:
“Though data warehousing might be costly, it’s a competitive advantage for businesses in the long term. The amount of data is tremendously growing, and those who don’t analyze it to get insights are likely to lag. Inspired by an increasing trend of maximum data collection, companies analyze terabytes of data. When you own the data and dive deep into understanding it, you know what would await you in the future, but you should understand that without a single data warehouse, it’s hard to get complex insights.”

Do you feel unsure you can define which infrastructure, on-premises or cloud, is optimal for your business? Let us know! Oxagile’s experts will be happy to help.

The ETL process moves data from source systems into a data warehouse in five structured steps. Thus, raw data is being prepared for analytics and reporting.
Typical ETL workflow includes the following steps:
This pipeline allows companies to combine data from many systems and analyze it through dashboards, reports, and long term trend analysis.
L1, L2, and L3 describe different maturity levels of a data warehouse environment. The classification reflects how complex the architecture and analytics capabilities are.
Below are simplified explanations. In practice, definitions vary by architecture, vendor tools, and platform scale, and teams usually assess factors such as data volume, number of integrations, ETL pipeline complexity, concurrency needs, and governance requirements:
As companies collect more data and expand analytics usage, they often move from L1 toward L3 platforms.
There are several architectural approaches used when designing a data warehouse. Each approach defines how data flows from sources to analytics environments.
The most common types include:
These approaches differ in structure and implementation order. Organizations can select a model based on scalability needs, data complexity, and analytics requirements.
Transactional databases record activities such as purchases, user logins, or support tickets. A data warehouse stores historical data from many operational systems and structures it for analytical queries.
Key differences:
Companies often move data from transactional systems into a warehouse through ETL pipelines to support long term analytics.
Implementing data warehouse infrastructure follows a structured process. Teams analyze business requirements, design the architecture, and deploy analytics pipelines. A typical implementation workflow includes:
After implementing data warehouse infrastructure, organizations gain a centralized data environment for reporting, analytics, and decision making.

