












This website uses cookies to help improve your user experience




Data-driven revelations are like a truth serum, instantly uncovering every little thing that needs to be changed, corrected, or eliminated. That’s why it’s so frustrating when the way to this valuable quantitative feedback becomes a swamp filled with disconnected figures of disparate formats and structures, making your business get bogged down and miss hundreds of opportunities before you reach the essence.
No surprise the number of Internet searches on things to consider when integrating data from multiple sources prevails over inquiries about follow-up data analysis.
However, since this topic is extensive, the answers found often tend to delve deeper into contradictions and further confuse the curious researcher.
But, luckily for you, you’ve clicked on the right page. Oxagile’s data engineer expert Ivan Zolotov will answer all of the most frequently asked questions that businesses face during any data integration process.

Ivan Zolotov — data engineer equipped with 10+ years of data integration expertise and 15+ successfully completed big data projects, involving the development and structuring of data integration processes.
Data integration means combining and structuring data or metadata related to our data from multiple sources with the goal of aggregating information in a way that will let us effectively utilize it for addressing specific tasks and queries.
Sometimes it’s not necessary to pull massive amounts of data from third-party data sources into our repository. Metadata might be just perfect. What I mean here is that we can tell our repository that there is certain data, its location, and give instructions on how to handle it.
It can really make all the difference. For example, I once had a project where I had to copy 2 petabytes of data, which in practice took as long as four days. It’s not a big deal in the timeline of the universe, but in terms of any business — a pretty tangible downtime.
There’s no need to spiel here, because the answer is obvious — data integration is extremely important. Most often, data for different tasks is stored in different repositories with different mechanisms of access within one company. For example, some data is accessed quite rarely, so we keep it in a data warehouse designed for long-term data storage. While there is data where a millisecond response is important, so, obviously, we keep it in storage with a different access pattern.
But here’s the thing: many business issues tend to appear unexpectedly, requiring prompt solutions. That’s why it’s so crucial to always have a complete set of data from various sources at your fingertips. Only this way can you always see a comprehensive picture of what’s happening in your business.
With tons of custom options, the variants of data sources are practically endless. But if we’re talking about the most popular ones, I’d single out these three main sources:

API access to data is the case when you interact with third-party data providers.
Relational databases are a way to organize and store data in a structured manner using tables. Despite the fact that they have been actively used for about 40 years already, they are still quite good in their niche and have no equals when it comes to dynamically joining data from different tables.
Object storages or file repositories, such as Amazon S3, Google Bucket, or Azure, are basically virtual limitless storage spaces where you can collect files with unique IDs and retrieve/read them quickly using the respective IDs. The retrieval of data from these storage systems is just as prevalent as reading from relational databases.
Many businesses today, guided by internet wisdom, really become convinced that cloud solutions, NoSQL, big data, and so on will be much more beneficial for them and request such changes, which, based on my own experience, turn out to be justified only in about half of the cases.
Internal may include the company’s data warehouse, data lakes, and logs, while examples of external include APIs, web scraping, and public data sets.
The division has more to do with how access to the data is organized. If it’s internal data — we can use it any time we want. If it’s external — we need a subscription.
For a data analyst, the original source of the data doesn’t hold much significance. Whether it’s data from YouTube or any other source, the analyst typically interacts with it in a standardized manner.
On the other hand, the engineer responsible for extracting data from YouTube needs to understand the source. But the thing is that the process of scraping data from YouTube videos itself falls under the notion of data integration too.

I would scrap a million clips and put that metadata in some storage, and then I would provide my clients with an API, which they could access to retrieve specific data.
Suppose our data is stored in the logs. What if we want to pull useful information from the voluminous files there to count and analyze the number of unique users per day?
I’ll start with the most inefficient way — to parse all the entries in our logs and extract necessary information. Why is it inefficient? Every time we get a similar task in the future (to count the average time of each user’s session, for instance), we will need to re-do the work already done.
What approaches to data processing can come to the rescue in this case? We have two main options:
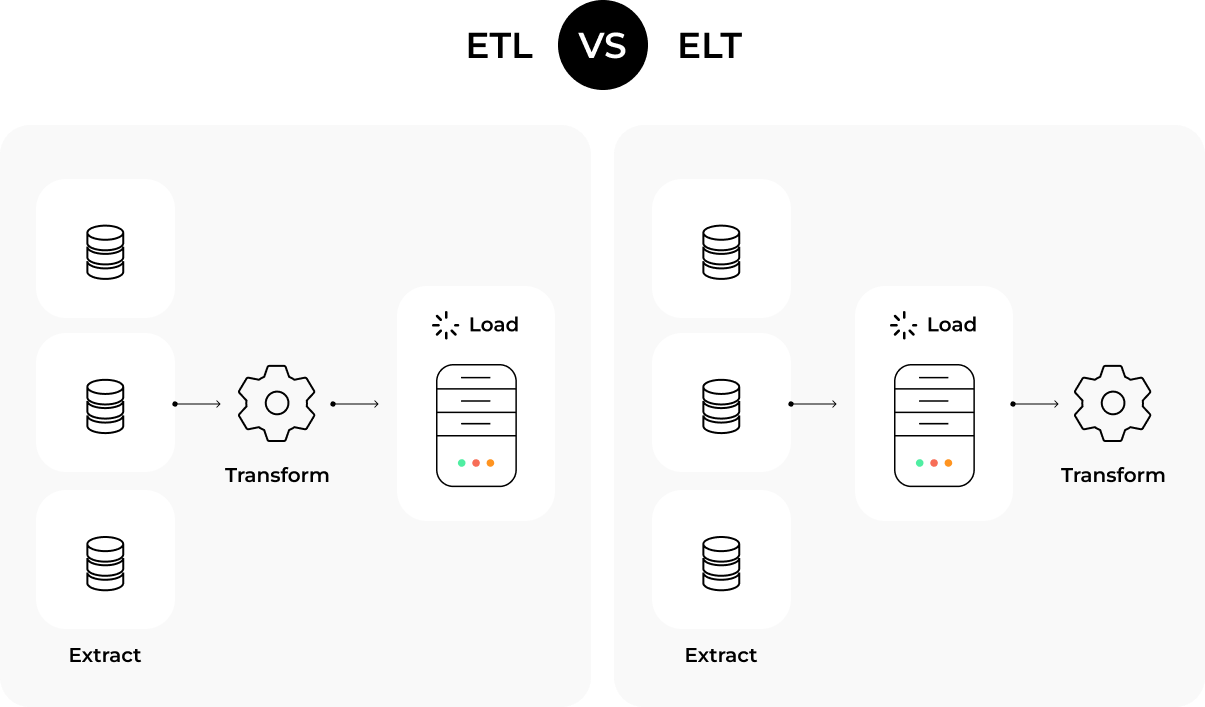
Based on my experience, I can say that ETL is more commonly used for working with a data lake, while ELT is associated with a data warehouse.
However, it all boils down mainly to what technologies you’re using. For instance, if you actively use the RedShift repository and invest in it, it would be advantageous to leverage the power of this cluster for processing data from multiple sources and employ ELT.
To give you a better picture, let’s first look at an example of a common, but very impractical approach to data integration where things don’t initially go well.
Imagine that some “N” company has a part of their data stored in a relational database, some stored in a cloud-based storage like Amazon S3, and some on remote servers accessed via API.
And then this “N” company has its day “X”: to urgently demonstrate a comprehensive audit with aggregated data over the past three years to a potential high-profile client.
And since this company does not use any common system that would always integrate data from multiple sources, the data engineers write code that first has to pull the data from each source. And, of course, each different storage requires a different code.
The data is finally calculated, the client is satisfied, everyone is happy. But a couple of weeks go by, and a new request comes in: a new client needs a slightly different type of aggregation now… And this whole code endeavor begins all over again.
However, there exists a solution that eliminates the need to reinvent the wheel each time, known as a data catalog.
It’s an abstract pattern that is basically a unified metadata repository. It allows for standardizing the entire data workflow, including the data integration process, of course. We overlay an additional layer of abstraction on top of all our data repositories, wherein any developer can work with familiar entities, such as tables and databases.
Besides, the data catalog also offers one more big advantage — the ability to restrict access rights and use role-based policies.
In fact, data integration steps may differ depending on the specific data catalog used, but to avoid abstract reasoning, let’s see how it works using the example of Amazon Glue Data Catalog.
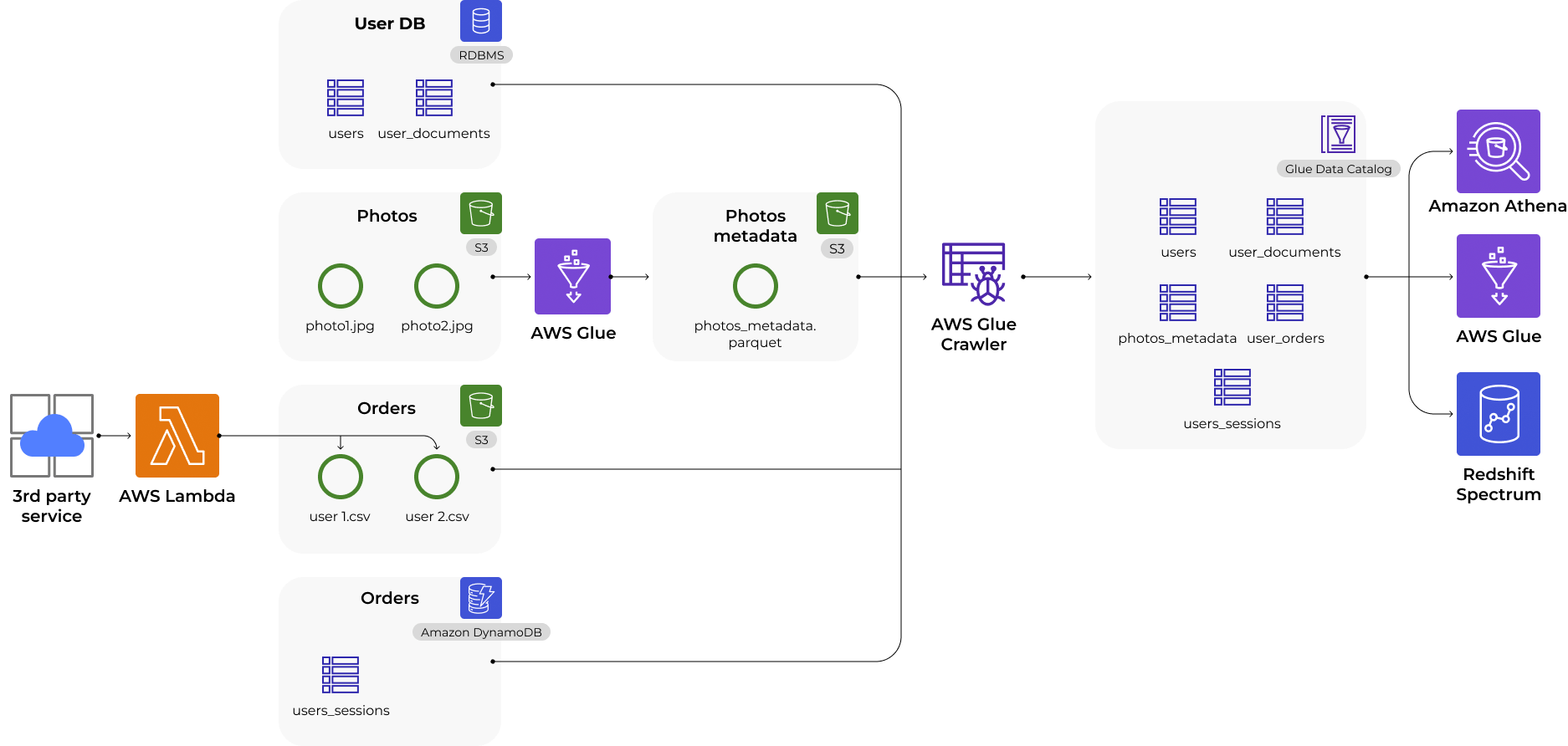
If you use the Amazon ETL component called Glue Crawler, you can just specify the place in Amazon S3 storage where the files are located and wait for it to analyze the data and create an entry in the catalog. As a result, you’ll get a database and a table with all the needed data. This entire process takes just a few clicks.
And this is one of the main advantages of any data catalog — the ease of scaling. We can easily automatically add a new record to the data catalog, which will also instantly be included in the analytical pipeline.
The nice thing about Glue Crawler in particular is that it can also read data from multiple sources including relational databases that do not even lie within the Amazon storages.
And the best part is that while metadata is added to the data catalog to make it easy to work with, the data in the Amazon S3 storage remains unchanged.
Once we have started our data catalog and got the list of tables and the database in our console, we can use the widest set of tools to analyze this data.
For example, Amazon Athena or Amazon Redshift are tools that allow you to run SQL queries on data stored in Amazon S3. Both of these instruments require metadata, which is exactly what is stored in the Glue Crawler directory.

Make sure that everything you do is right for your business with accurately integrated data from multiple sources.
Here I’ll probably have enough experience to compile even a short list. But a little spoiler — all of these issues can be resolved with ease.
One of the most common tasks on projects is usually choosing between different tools, such as Amazon Athena, Redshift, and Apache Spark. Clients often prefer to hire SQL engineers, guided by the fact that they are much easier to find than Spark specialists. However, once a client has the right process of extracting data from multiple sources as well as a proper data catalog structure in place, he is free to choose any option and can be no longer limited to certain technologies.

In one of my previous projects, I also noted a very interesting thing when choosing technology to move from on-premises storage to the cloud: the majority of open sources that compare tools tend to prioritize factors such as the speed advantage of a particular system, claiming that if one is 3% faster when dealing with large datasets, it’s definitely worth trying out. However, the truth is that such a percentage difference in performance brings almost no real advantage to the client, while there are more practical aspects to consider. For example, it is more important that the data processing does not cause basic errors that might otherwise demand considerable time and effort for rectification, slowing down further data analysis and postponing getting timely insights.

