

The story in brief

The client’s portrait
A Fortune 500 corporation with thousands of technology patents and dozens of subsidiaries around the world.

Their quest
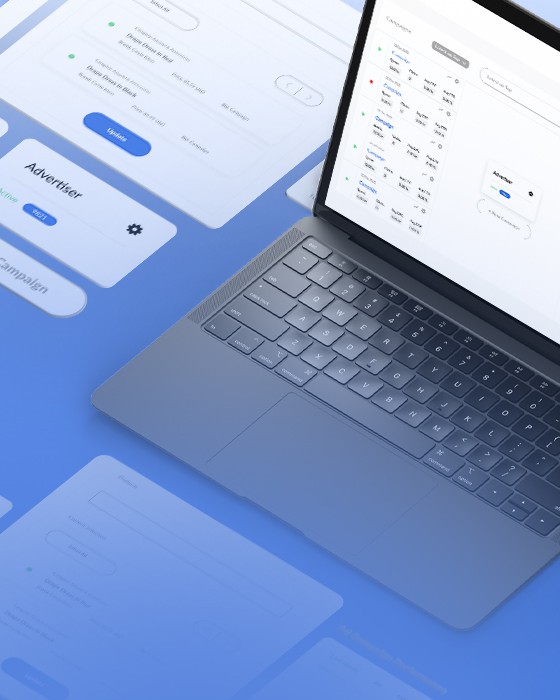
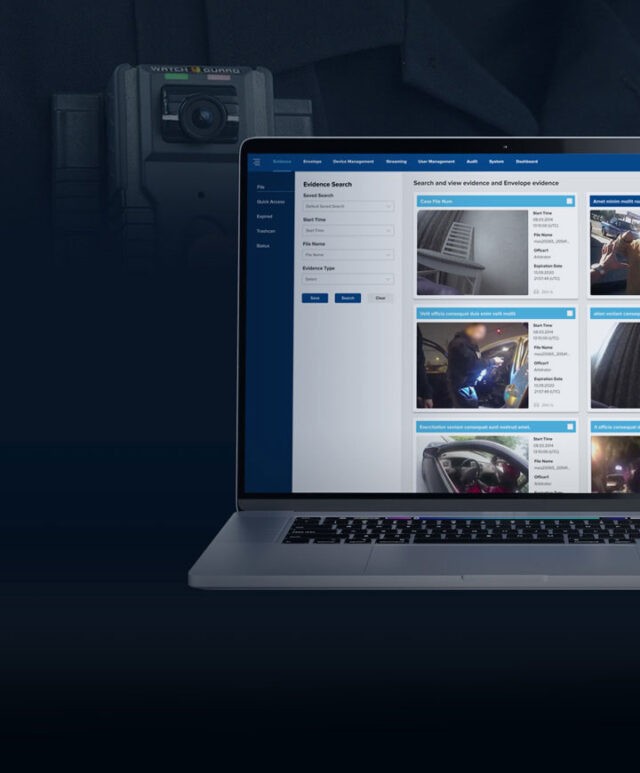
Developing a comprehensive computer vision-driven tool for the specific needs and requirements of the police force.

Our answer
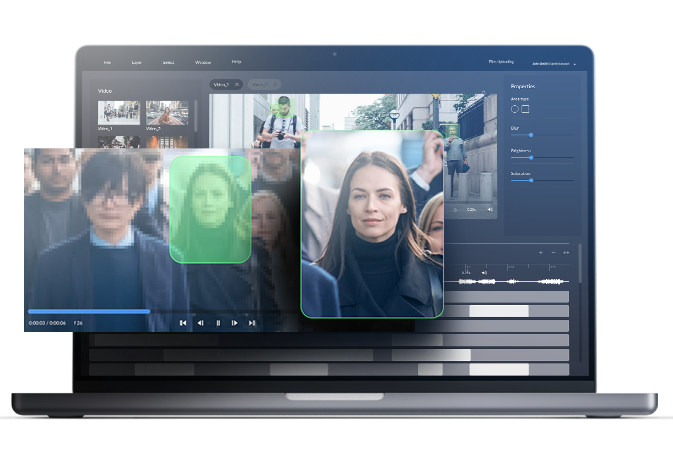
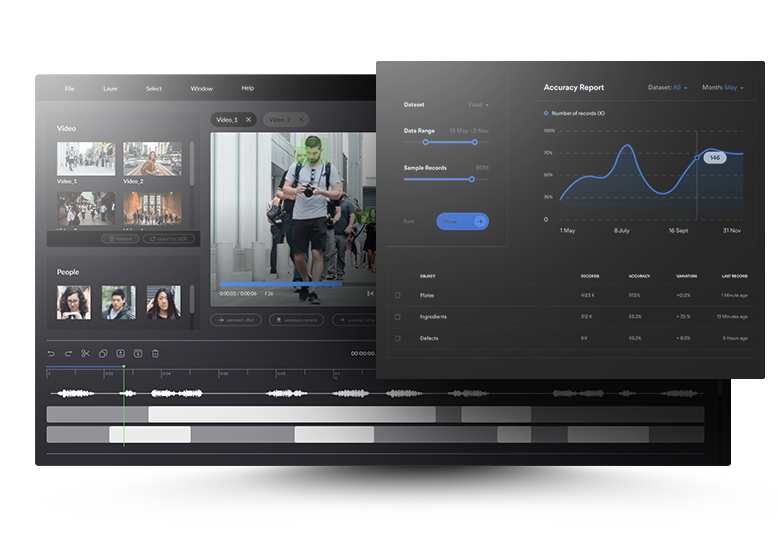
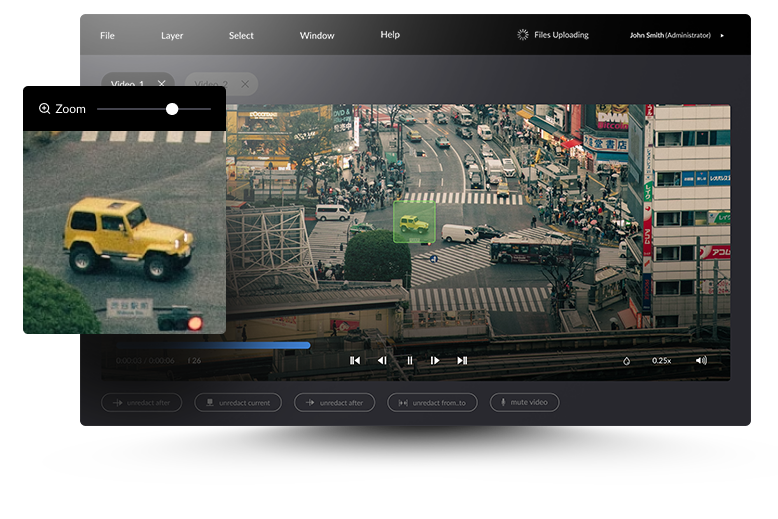
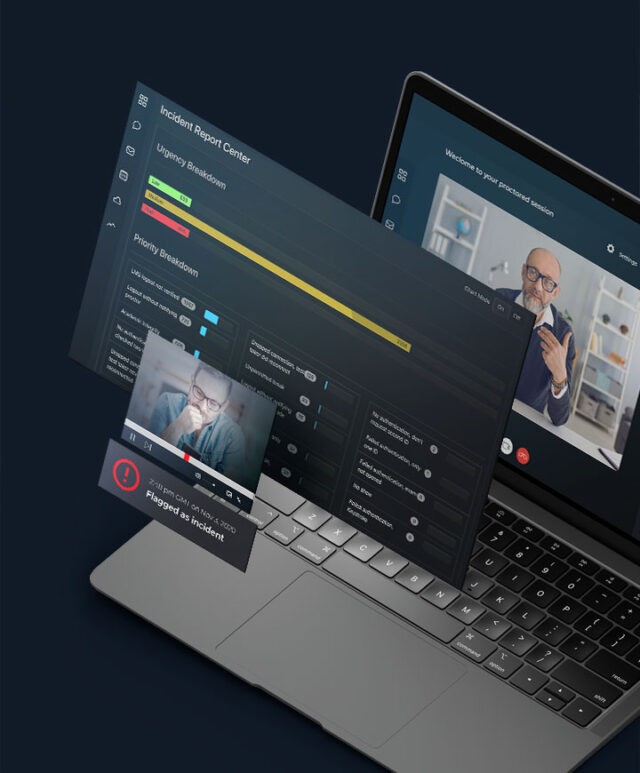
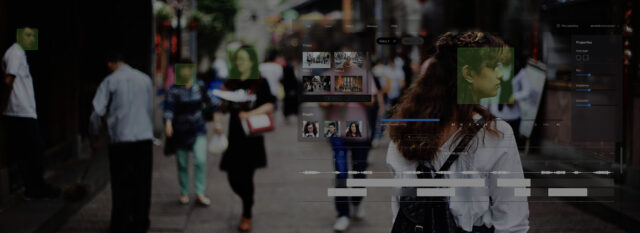
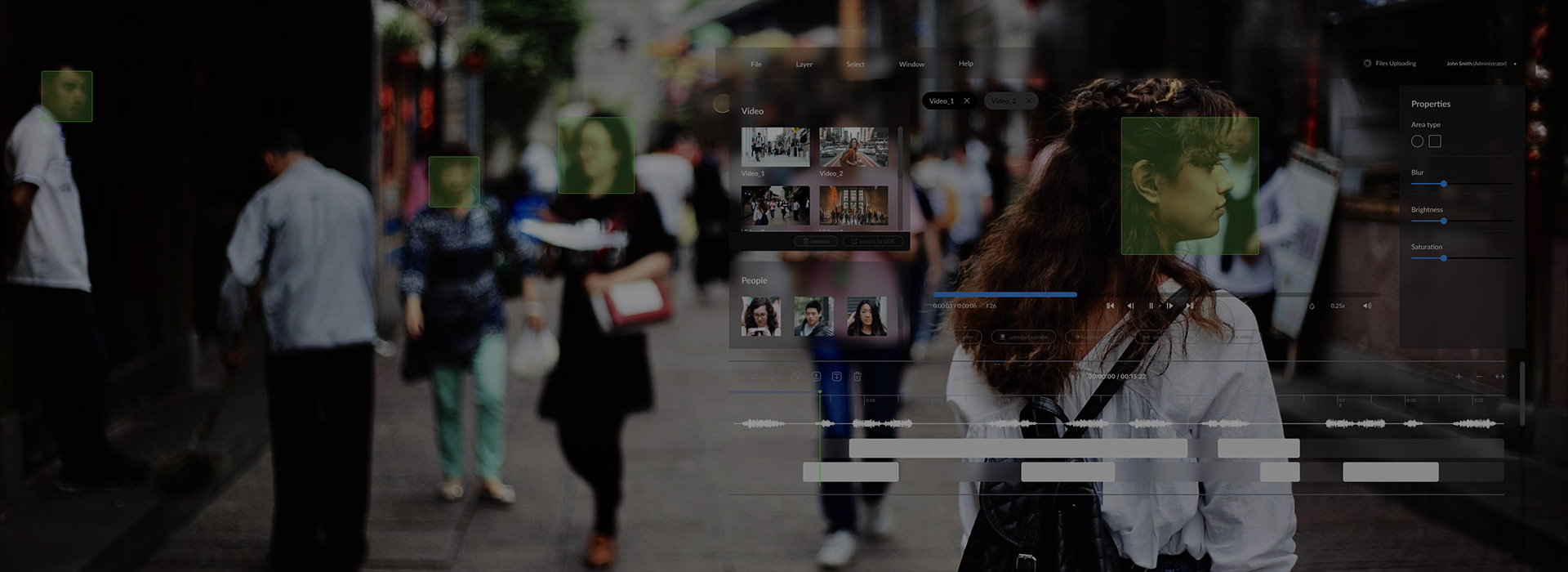
An AI-driven computer vision solution that extracts all unique faces, objects, and vehicles from camera footage, provides specialized video editing tools, and produces detailed reports with metadata for every video frame.