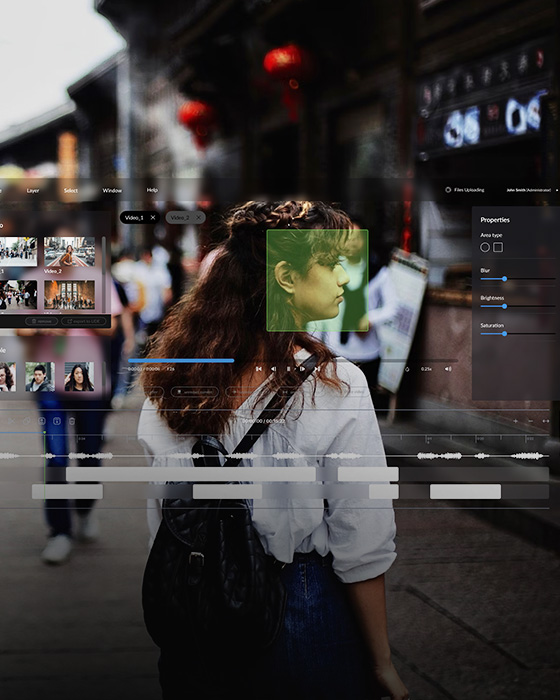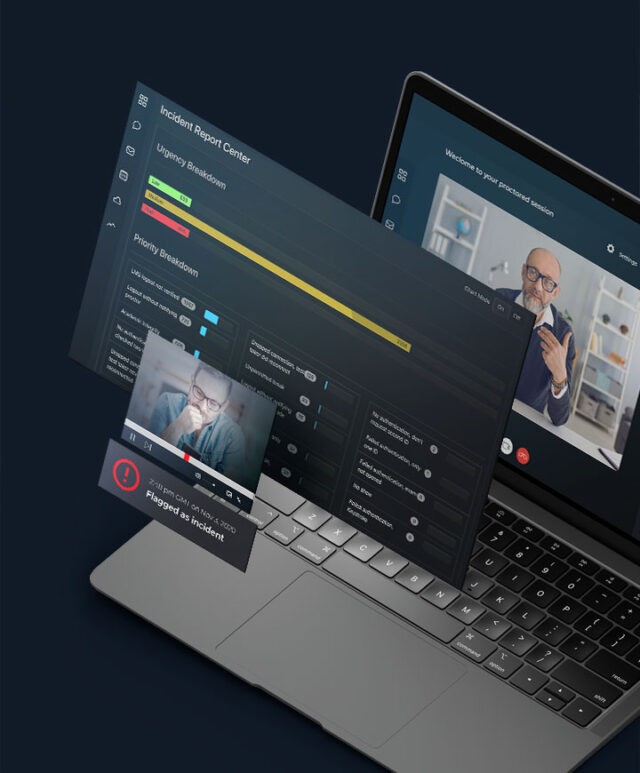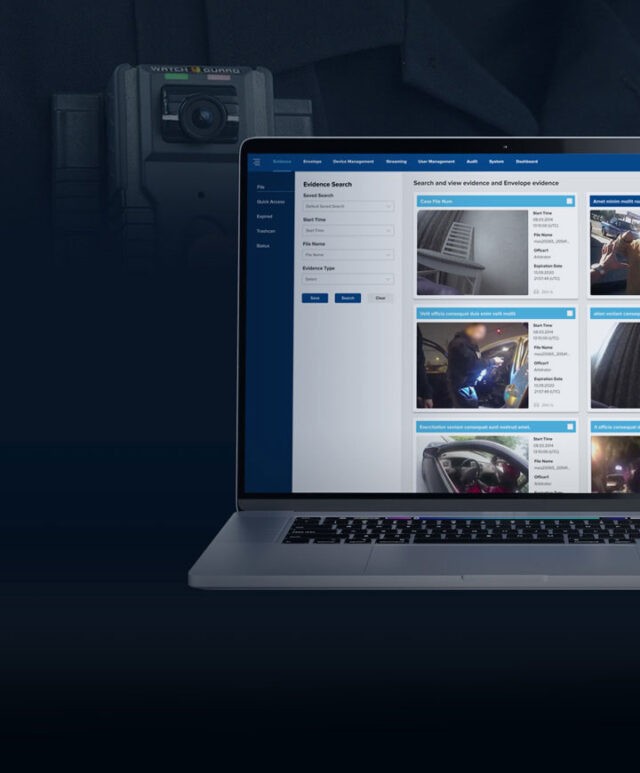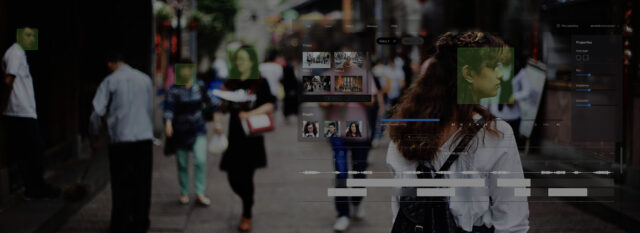


Multi-year track record in video and image analysis applied to real urban security challenges. Crowd dynamics, perimeter monitoring, suspicious behavior flagging, and violence detection, across public and private spaces.

Since 2005, we've built computer vision systems for clients who can't afford margin for error. Broadcasters, healthcare providers, retailers, and public safety operators, each with their own data constraints, latency requirements, and compliance obligations.








The conditions vendors test for aren’t the ones you’ll face in production. The real engineering challenge starts after the proof of concept, when computer vision systems are adapted to the operational realities they weren’t originally built for.
Generic models trained on benchmark datasets degrade against your specific lighting conditions, camera angles, and object variance. The gap between lab accuracy and production accuracy is rather small. Custom training on your data, not a fine-tuned version of someone else’s, is the only reliable fix.
Healthcare imaging, law enforcement video, and financial biometrics each carry distinct regulatory constraints around data residency, retention, and access control. Generic systems are rarely architected with those constraints in mind, nor do they pass a serious vendor qualification review.
Real-time detection at scale forces architectural decisions that off-the-shelf platforms leave to you: edge vs. server-side deployment, frame batching, model compression, hardware selection. Get them wrong and you’re choosing between a system that’s fast enough or accurate enough, but not both.
Pre-trained models output in formats and at throughputs that hardly ever match your existing stack. The model itself is often the easy part. Building the serving layer, designing the API contract, and fitting the pipeline into your infrastructure is where most PoCs stall and timelines slip.
Object recognition solutions spanning detection, tracking, and behavioral analysis, built for the complexity of real-world environments.






Bringing together computer vision and operational expertise to improve safety in complex real-world environments.
Precision image processing with a strong focus on signal integrity, noise characteristics, and spatial resolution.
High-accuracy visual recognition that performs consistently across varied conditions and contexts.
Non-contact thermal screening with clinical-grade accuracy, designed for high-throughput environments.
Pose estimation, behavioral pattern mapping, and everything between, applied across safety monitoring, sports analytics, and proctoring.
Sentiment and affect recognition through facial analysis for marketing, e-learning, public safety, and beyond.
Object recognition solutions built around your data, environment, and operational constraints, then deployed where the problem lives.
 Safety
Safety Multi-year track record in video and image analysis applied to real urban security challenges. Crowd dynamics, perimeter monitoring, suspicious behavior flagging, and violence detection, across public and private spaces.
 PROCTORING
PROCTORING Enterprise-grade proctoring built on biometric analysis. Facial expressions, posture shifts, and gaze patterns are read in real time to assess student engagement and flag irregularities. Every exam session stays audit-ready and regulation-compliant.
 AUDIENCE INTEL
AUDIENCE INTEL Face and emotion recognition applied to audience analytics. Demographic profiling, attention curves, and reaction mapping give broadcasters and platforms the data they need. Sharper content decisions, more precise ad timing, and recommendations that reflect actual viewer behavior.
 MARTECH
MARTECH Object and emotion recognition that reads actual customer responses, letting brands move beyond assumed preferences when shaping messaging and creatives.
Loyalty programs gain a practical edge too: recognized returning customers get a seamless, personalized experience from the moment they walk in.
Tensorflow • PyTorch • Core ML • MXNet • Caffe2 • Chainer • Theano • Sonnet • Microsoft Cognitive Toolkit
Kurento’s computer vision module • NVIDIA DeepStream SDK • TensorRT • GStreamer
Google Cloud AI • Amazon Machine Learning • Azure Machine Learning
Server • Desktop • Edge devices • Cloud • Mobile • Tablet

Yes, and it’s one of the more demanding configurations. Real-time performance depends on model architecture, hardware, and how the pipeline is optimized for latency.
Our video object detection software is built to handle continuous streams without frame-drop or lag in detection, whether deployed on edge devices or server-side infrastructure. The specific throughput and accuracy trade-offs get scoped during architecture design based on your environment and volume.
Image classification assigns a label to an entire image. Object identification software goes further, locating specific instances within a frame and identifying what they are.
Object detection combines both: it draws bounding boxes around objects and classifies each one, often tracking multiple targets simultaneously. In practice, most production systems use detection as the foundation, with recognition and classification layered on top depending on the use case.
Data governance is treated as an architectural concern, not an afterthought. Our object detection services are developed under ISO 27001-certified practices, with data handling protocols defined at the project outset, covering storage, access control, anonymization where required, and compliance with relevant regulations.
For sensitive deployments, on-premise processing is an option that keeps data within your own infrastructure entirely.
It varies by complexity, data availability, and how well-defined the target use case is. A focused PoC, single object class, controlled environment, clear success criteria can be delivered in two to four weeks. Multi-class detection in uncontrolled conditions with custom training data takes longer. The scoping conversation upfront is where that timeline gets grounded in reality.
Yes. Integration is part of the delivery, not a separate engagement. We work with your existing stack, APIs, data pipelines, front-end interfaces, or embedded systems, and design the model output format and serving layer to fit how your infrastructure actually operates. Where legacy constraints exist, those get identified and addressed during the technical discovery phase.