










This website uses cookies to help improve your user experience




Imagine this: your payment system appears completely stable, but revenue is quietly slipping through the cracks. Impossible?
The truth is that payment failures rarely manifest themselves as full-on outages. More often than not, they appear as subtle hiccups: a small drop in authorization rates, a slight increase in soft declines, a somewhat slower 3D Secure flow. Individually, they may seem like a minor bump on the road. But at scale (or over time), they can become financially crippling for your business.
The modern payment integration development paradigm is made up of several interconnected components:
Payment reliability and observability mechanisms are embedded into these foundational components of virtually any fintech solution. Placed strategically across the system, they continuously monitor the overall state of the payments pipeline and take specific measurements to detect anomalies and deviations from expected outcomes.
These capabilities are equally important during payment gateway migration and afterwards. During PSP migration, they help assess each transition phase and make informed go/no-go decisions. And once the migration is over, they are essential for identifying hidden bottlenecks and reacting to payment operations incidents quickly.

We spoke to Maxim Narushevich, Python Engineer at Oxagile, who has hands-on experience working on numerous projects that require thorough payment monitoring setups. Together, we look at the most common payment observability and reliability challenges and the ways to handle them successfully.
Key takeaways:
Surprisingly enough, the stability of your platform in general might not mean you are on your A-game in the payments department.
Payments are first and foremost a business function and are more nuanced in terms of operational KPIs.
Example: your system health dashboards can remain evergreen and report a stable 99.99% API uptime, outstanding peak performance, and healthy CPU/RAM usage, but your payment system may be bleeding internally without you knowing that you are in trouble.
Expert opinion:
“General infrastructure monitoring will never tell you that you are getting an unusually high number of soft declines for a particular payment method, plummeting conversions for a specific BIN range, or 3D Secure timeouts in a certain region. From the outside, things will be looking great with no reasons to worry. Under the hood, you will be losing revenue and your customers’ trust.”
One important thing to understand is that payments reliability is not measured in uptime percentage or resource utilization. It’s measured in a stable money flow and user behavior leading to increased loyalty to your goods or services.
In this unfortunate case, your business may be taking financial hits on a regular basis.
First, you start losing revenue to undetected failures and declined payments with no retry logic. When issues escalate, customer support gets flooded with tickets, inflating operational costs and customer compensation expenses.
Second, customer loyalty and retention take a dive, dragging down the very important LTV and MRR metrics. If you fail to address mounting issues, you may see long-time subscribers switching to competitors.
Unlike many other workflows in your system, your payment infrastructure may have multiple points of failure, both on your end and outside. Being able to constantly check its vitals and interpret them in a meaningful, actionable way is crucial for any business.
Keep in mind that even a 1% drop in approval rates at scale can cost you more than an entire year’s worth of processing fees. What would a smart risk hedging solution be in this case? Correct — investing in payment system observability often yields better ROI than chasing marginally lower transaction costs with a new payment service provider.
Maxim notes:
“Payment observability isn’t a gimmick or luxury. It’s good old risk management. Every blind spot in your monitoring is a potential revenue leak that compounds daily.”
Payment declines fall into two categories: technical issues and user errors.
The overwhelming majority of these and other issues can be detected, logged, and immediately investigated using diagnostic data collected from the network, PSP postbacks, the security system, and internal logs.
Payment observability is the technical ability to see, both in real time and historically, how every payment flows through your systems and to translate that visibility into better control and ease of troubleshooting.
It combines infrastructure telemetry data (logs, metrics, traces, events) with business signals (authorization and approval rates, latencies, drop-offs, discernible error patterns, and fraud check outcomes) across the entire payment journey.
This unified view empowers technical teams to detect anomalies early, understand root causes quickly, and respond in ways that efficiently protect revenue and customer experience.
In practice, this requires a centralized data collection and reporting pipeline that ingests data 24/7 from various sources. It then assesses the health of the payment system based on technical and business KPIs, such as:
Ideally, the system should be able to combine various data aggregation and visualization methods and serve as a single source of truth for business stakeholders, engineering, and support teams.
Expert opinion:
“The difference between reactive and proactive payment operations is quite simple: reactive teams discover issues through support tickets, proactive teams spot anomalies in their telemetry before the first customer submits a complaint.”
Architecture is pivotal for true observability and a reliable day-to-day revenue flow.
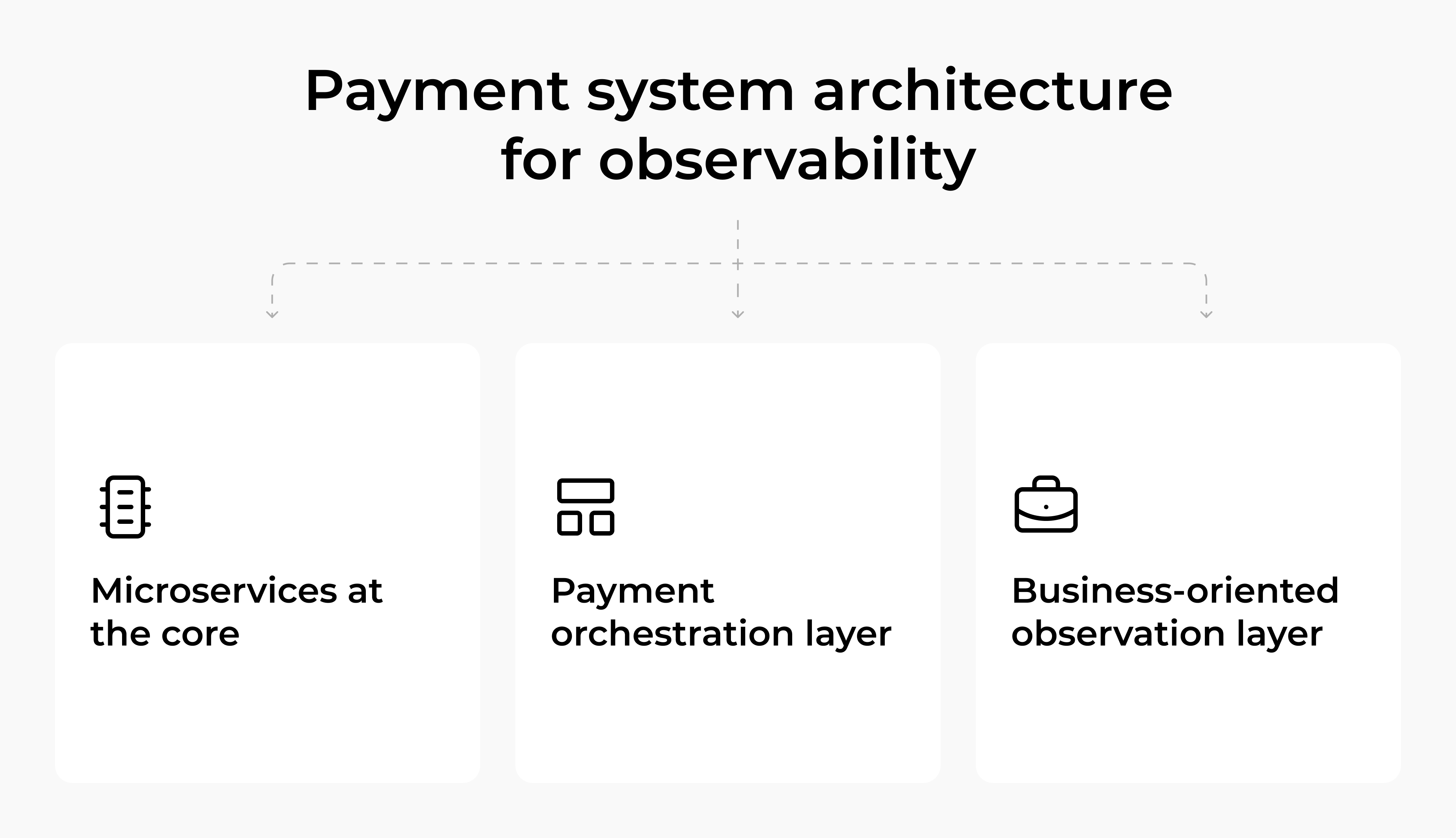
A distributed, microservice-based, and event-driven system architecture is a perfect foundation for building an end-to-end data collection pipeline. Coupled with an API-based payment orchestration layer detached from the rest of the system and hosting all of the security, PSP routing, and error-handling logic, it facilitates low-level event logging and traceability across all payment flows.
Event-driven design supports queues, topics, and asynchronous processing, giving the system a greater degree of protection from performance hiccups on the PSP’s side. It also allows for a more granular, detailed way of logging payment system events for greater observability.
This abstraction layer lets the system automatically switch to alternative providers when one begins to show signs of rapid degradation. This automation frees up the team’s capacity to address the issue without disrupting the flow of payments.
Having a payment orchestration layer also facilitates the integration of new payment methods or migrations that take place without major changes to the main application that continues to fulfill its function.
When telemetry data flows to a centralized data repository through event streaming or log aggregation, the monitoring system can provide a detailed, real-time breakdown of the entire payment journey for a particular transaction or all transactions at once.
From checkout to completion, the system presents chronological views with statistics segmented by PSP, geography, time period, payment method, and amount.

Oxagile covers all the bases: architecture planning, observability design, implementation of monitoring solutions, configuration of automated alerts, and creation of incident response playbooks for your support team.
Learn more about our professional payment gateway integration services, and feel free to contact our team.
For real-time payment visibility across infrastructure, payment service providers, routing, security, and business metrics, tooling choices matter significantly.
Dashboards provide visualization, but observability requires event correlation, alerting, and defined incident response processes.
Maxim explains:
“If your idea of 24/7 payment monitoring and incident response is a team staring at screens and taking night shifts, I’ve got great news for you. These days, it can be an engineered and largely automated capability that turns unavoidable payment failures into measurable, controllable, and recoverable events.”
Robust, future-proof payment observability must combine the following basic elements.
To get the full picture, you have to be able to capture the following crucial pieces of data:
All of these readings must be fed to a centralized database and not hardcoded into user-specific dashboards.
Infrastructure monitoring is immensely helpful, but only if its data can be tied to or used for generating specific business-relevant signals, for example:
The tools you choose for building your observability platform must support custom signal mapping, SLOs, and Service Level Indicators (SLIs).
Dashboards, reporting, and the underlying data layer should be configured in a way that allows not just real-time tracking, but detailed drill-downs into historical data for retrospective incident analysis.
Expert opinion:
“In payments, a 2% dip can be a one-off glitch or a recurring trend. The difference becomes clear only when you can trace it back through historical data.”
When things go south, the system should be able to automatically assess issue severity and send alerts to predefined recipients across a number of channels, such as email, messengers, and text messages. At the same time, it should continuously monitor the situation, escalating alert levels when needed and suppressing them once conditions go back to normal.
These rules are often referred to as incident response playbooks, which are checklist-like scenarios that are automatically executed in case of an incident.
The role of playbooks is hard to overestimate. They provide a clear, agreed-upon algorithm for handling non-standard situations that helps minimize the impact and get things back on track within the shortest time possible. A good playbook should span every step of the process:
Having a clear, step-by-step playbook for every potential case can be a game-changer for 24/7 support teams working with payments, as it helps pinpoint the issue and fix it before it takes a heavy toll on business continuity.

Discover how Oxagile successfully migrated over 1.5 million live users to a newly-integrated payment gateway without losing a single bit of data.
The team also implemented a robust payment observability system based on playbooks, end-to-end monitoring, strict SLAs, and business metrics.
Every company that processes payments eventually learns the same lesson: you can’t manage what you can’t see, and you can’t protect revenue you don’t monitor. You may learn this lesson the hard way, or build safeguards and optimize your processes to the point where payment incidents are no longer a disaster, but a minor fender bender on your daily commute.
In modern systems, payment reliability and observability are not about reacting to red lines on your monitoring dashboard. They are much more about implementing and automating an early warning system covering entire workflows so that some issues are resolved automatically, and the remaining ones get immediately picked by support teams who know exactly what to do.
Practice shows that businesses that invest in this capability don’t just survive incidents better, they attain a level of operational resilience and customers’ trust that becomes their competitive advantage.
Oxagile covers the full range of payment infrastructure development: microservices architecture, orchestration layers, real-time monitoring, and incident response automation.
Our fintech team brings deep expertise in creating payment systems that scale securely and offer complete operational visibility.

Payment system reliability is the ability of your payment stack to process transactions consistently, without unexpected drops in approval rates or customer-visible errors. It matters because even minor issues quickly translate into lost revenue, higher support load, and erosion of customer trust.
Start by enforcing payment SLA monitoring and designing for failure: having multiple PSP options, clear routing and fallback logic, payment observability tools, and playbooks for common incident scenarios. With this foundation, you can keep accepting orders and settle them safely later instead of going offline whenever one provider misbehaves.
Monitoring payment integrations effectively goes beyond checking whether APIs are “up” and latency is within limits. You should also track authorization success rates, 3D Secure outcomes, error patterns by payment service provider and region, and checkout abandonment so that monitoring is meaningful for revenue and customer experience.
It requires combining technical telemetry (errors, latency, timeouts) with business signals (success rate changes, spikes in declines, unusual traffic by geography or method). Once you fuse these data streams, detecting payment issues in real time becomes much faster, and teams can act before customers start complaining.
Automation helps handle payment failures by triggering retries, shifting traffic to healthier PSPs, and generating automated alerts for payment systems and operators, supporting teams when thresholds are breached. By using tailored rules and playbooks, the process becomes predictable and controlled instead of chaotic, which reduces downtime and protects user experience and revenue.

