












This website uses cookies to help improve your user experience




Image processing, computer vision (CV), and machine learning (ML) often appear together in presentations and strategy decks, as if they naturally belong to the same family of techniques. They sit on the same slide, connected by neat arrows, promising to turn raw pixels into meaningful insights. However, these methods evolved from different eras, with distinct goals and mathematical mindsets.
Some may frame the distinction as computer vision vs image processing, but such a comparison is also not completely accurate, as it is frequently oversimplified: the truth is that these two operate on fundamentally different layers of the pipeline. So, if you step away from the slide into a real project, the boundaries become far more important than they may seem.
Treating these approaches as interchangeable often leads to unnecessary complexity, budget overruns, or disappointing accuracy. That’s why support from a custom computer vision development company that understands how different methods behave in real-world conditions is essential.
In this article, we’ll share our first-hand experience and provide a clear examination of how these approaches differ, why they emerged, and how they complement one another. We explore the historical progression from classical algorithms to deep learning, explain why data availability typically dictates the winning method, and examine real scenarios where trend-following decisions harm ROI.

Guiding us through the intricacies of visual AI is Dmitry Pozdnyakov, AI Engineer at Oxagile and Associate Professor, PhD. The insights shared throughout this article are drawn from an in-depth interview with Dmitry, whose perspective helps clarify how image processing, computer vision, and learning-based methods evolved and how they are applied in real-world systems today.
Before choosing a solution or comparing methods, it helps to return to the essence of each term. All three approaches work with visual information, but the similarity ends there.

Traditional image processing comes from mathematics and signal processing. It focuses on transforming pixel values: calibrating sensors, removing noise, balancing brightness, correcting distortion, and restoring detail. It prepares an image for any higher-level reasoning but does not attempt to interpret what the image contains. Its job is to make the data stable and trustworthy. This is why discussions around image processing vs computer vision often overlook the fact that processing stabilizes the input, while CV interprets its meaning.
Computer vision (CV) operates on top of that foundation. Once the image has structure, computer vision algorithms look for meaning: detecting objects, tracking motion, segmenting regions, identifying defects, and interpreting behavior. The goal is to extract insight, not simply to refine the visual appearance.

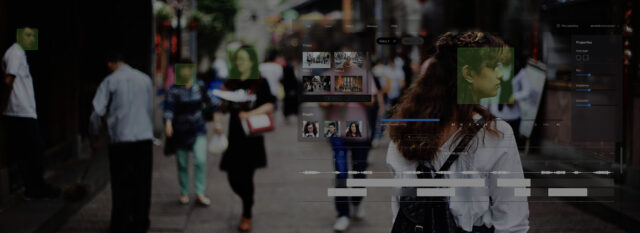
How do you enforce safety rules in a crowded enterprise space without turning it into a manual surveillance nightmare?
In one real-world project, computer vision was used to do exactly that — automatically detecting people, tracking movement, identifying faces, recognizing mask usage, measuring body temperature, and monitoring social distancing in real time. The system didn’t just “see” video streams; it interpreted behavior and triggered alerts where rules were violated, turning raw camera feeds into actionable operational insight.
Machine learning (ML) and deep learning (DL) form a separate branch of development. These methods were originally built to analyze numerical data of any kind. Their arrival in CV began when researchers started treating images as structured datasets — arrays of pixel values that could be processed by trained models, not manually. This idea unlocked new capabilities and quickly reshaped the field. This is why the contrast of computer vision vs machine learning can be misleading: ML was never designed specifically for visual tasks, yet it became essential once images were reframed as numerical data.
This shift explains why two tasks that look equally simple may require very different technical strategies. A visually straightforward case may involve subtle semantic distinctions that only a learning-based model can capture. At the same time, a seemingly advanced problem can sometimes be handled perfectly by classical algorithms if the structure is predictable. Understanding these nuances allows teams to choose solutions that are both accurate and economically reasonable.
Grasping how modern visual systems operate requires a look at what happens long before any algorithm recognizes an object or classifies a pattern. Every camera, sensor, or imaging device begins with raw data — and raw data usually has little resemblance to a clean, understandable picture. Whether it comes from an X-ray detector, a CT scanner, a thermal camera, or an industrial inspection line, the initial output is noisy, distorted, uneven, and often completely unintuitive to the human eye.
Traditional image processing emerged precisely to bridge this gap. It converts technical signals into images that humans (and later machines) can meaningfully work with. Early visual pipelines relied on a series of mathematical procedures designed to correct sensor-specific artifacts and turn chaotic pixel arrays into coherent frames: calibration, normalization, noise suppression, contrast adjustments, geometric alignment. Medical imaging is a prime example. The raw feed from a chest X-ray or CT machine is nearly unreadable without a long chain of transformations that restore clarity and structure.

The same logic drives thermal imaging. A raw thermal sensor does not output “temperature” in any human sense. Instead, it produces a stream of intensities that must be mapped to temperature values through calibration and normalization before becoming useful in diagnostics or monitoring. Only after this translation does a thermal frame begin to resemble the information clinicians or engineers expect to see.
Such preprocessing routines form the quiet backbone beneath nearly every modern visual system. They run on smartphones, security cameras, aerial drones, factory robots, and medical devices. Decades before learning-based models appeared, these methods carried the entire weight of preparing images for interpretation. And they continue to serve that role today because the first stages of visual understanding still rely on stable, consistent input.
Strong preprocessing remains essential even in the age of ML and DL. Learning-based models operate on structured, consistent data, and they depend on earlier stages to prepare it. Without this foundation, no classifier, detector, or segmentation network can reliably perform its task.
Growing datasets and increasingly complex problems eventually pushed researchers to explore methods beyond handcrafted filters. That shift opened the door to ML techniques designed to tackle semantic understanding rather than signal correction.
The shift from classical image processing to semantic understanding didn’t happen all at once. As soon as researchers had reliable ways to stabilize an image, a new challenge appeared: how to teach machines to recognize what the image actually contained. The earliest steps in that direction relied on machine learning, long before DL reshaped the entire landscape.
The early ML workflow revolved around extracting features (patterns that highlighted edges, textures, or contrasts) and letting a model learn how to distinguish one class from another. Engineers often designed these features manually, creating small filters that reacted to specific visual structures.
One well-known example involved Haar-like features: simple rectangular templates introduced in the Viola-Jones framework. These templates slide across the image and respond strongly to certain contrast patterns, transforming the raw picture into a long numerical vector of handcrafted signals.
Once these vectors were built, models such as Support Vector Machines (SVMs) took over. Their logic is geometric. Every image becomes a point in a high-dimensional space, and the model tries to find a boundary separating one class from another as cleanly as possible. In low dimensions that boundary is easy to imagine — a line or a plane. In hundreds of dimensions it becomes abstract, but the mathematics stay the same.
A growing appetite for accuracy eventually demanded methods that could learn their own features rather than rely on manual engineering, and that shift opened the door to DL.
The arrival of deep learning marked a turning point in the history of visual technologies. Earlier stages of computer vision depended on handcrafted features, domain expertise, and clever engineering. Those methods worked well for structured tasks, but they struggled whenever visual complexity increased. Subtle textures, overlapping objects, unpredictable lighting, tiny defects — each of these demanded new handcrafted tricks. ML could only go as far as its engineered features allowed.
DL approached the problem from a different direction. Instead of designing features manually, neural networks learned them directly from data. Layer by layer, they extracted edges, shapes, textures, and eventually semantic concepts. The more data the model received, the more expressive these learned representations became. For the first time, an algorithm could discover visual structure on its own, without relying on human intuition.
The impact was immediate. Classification accuracy leapt forward, object detection became dramatically more reliable, and tasks that once required months of manual feature design suddenly became achievable with well-prepared datasets and a suitable network architecture. CV entered a new phase, one where learning replaced engineering.
The influence of DL didn’t stop at semantics. As models grew deeper and training methods improved, neural networks learned to handle tasks traditionally linked to image processing: denoising, super-resolution, deblurring, color correction, contrast balancing. What once required specialized filters and mathematical models now became learnable transformations. For this reason, the old contrast of digital image processing vs computer vision became far less rigid once learning-based models began to cover both low-level correction and high-level interpretation.
As CV absorbed DL, the boundaries between processing and interpretation became less visible. But one factor remained decisive: deep learning thrives only when there is enough data to reveal the patterns it needs to learn. That dependency shapes modern decision-making more than any other technological trend.

Deep learning unlocks powerful capabilities in computer vision, but translating that potential into reliable production systems requires more than choosing the right model. Data quality, preprocessing pipelines, and architectural decisions all shape the final outcome.
To explore how these elements come together in real projects, learn more about our approach to computer vision development.
Technology discussions in CV often begin with methods:
But in practice, the starting point almost never lies in the method itself. The real constraints come from the task and from the amount of data available to support it.
Some problems simply don’t have enough material for learning-based techniques to function at all. If only a single image must be cleaned from noise or distortion, no model — neither ML nor DL — will have enough information to learn anything meaningful. Classical algorithms remain the only option. This is where teams rediscover the practical difference between computer vision vs image processing: one requires structured, meaningful data, the other operates purely on analytical transformations.
As soon as a few hundred examples appear, the landscape shifts. ML tends to outperform handcrafted algorithms once there is statistical variety to learn from. Methods like SVMs often beat even the most carefully engineered heuristics when the dataset reaches a proper scale. At that point, data begins to reveal patterns that analytical rules can only approximate.
The balance changes again when the dataset grows into the thousands or tens of thousands. DL becomes not just viable but increasingly dominant. Networks trained on rich, diverse data start discovering structures too subtle or too complex for both classical algorithms and traditional ML. With enough variation, a deep model learns to generalize, adapt, and outperform every other approach — sometimes dramatically.

This perspective highlights a simple truth: methodology follows data, not the other way around. Many real-world CV decisions boil down to understanding what the dataset allows. When the data is scarce, analytical algorithms remain essential. When the data grows, ML takes over. When the data becomes abundant, DL is the natural choice.
In theory, choosing a visual solution seems straightforward: the more advanced the method, the better the result. In practice, this logic routinely leads companies into avoidable losses. Projects stall, budgets inflate, and teams spend months tuning a sophisticated DL pipeline for a task that could have been solved by a lightweight library or even a single analytical filter.
The problem rarely lies in bad intentions. Businesses want to follow industry trends, adopt modern AI, and stay competitive. But without a clear understanding of how CV methods differ and what they actually require, teams often choose technology first and define the task second. That order almost always creates friction.
Consider a simple scenario: reading QR codes on a production line or in a warehouse. It sounds like a textbook CV problem, so teams may assume they need a DL-based detector. Vendors confirm that neural networks are powerful; demo videos look impressive; budgets grow accordingly. Meanwhile, the task itself has been reliably solved for years by classical algorithms that cost nothing, run in real time, and are available in a standard library like OpenCV.
The misalignment doesn’t end with underestimating classical methods. Many companies face the opposite issue: assuming a task is “simple” and can be handled with thresholds, filters, or a rule-based algorithm. Once the system enters real-world conditions, with inconsistent lighting, varied backgrounds, subtle defects, and shifting camera angles, the handcrafted logic collapses. What looked trivial on paper turns out to require ML or DL because the variation in visual input is too high for deterministic rules. Similar challenges appear in real retail environments, where lighting, camera placement, and customer behavior constantly change.
A third category of mistakes arises from unclear problem formulation. Businesses often request abstract goals like “detect product quality” or “identify fraud” or “understand employee performance”. None of these tasks can be solved with a single CV technique because each one hides multiple subproblems, each requiring a different method — from segmentation to tracking to anomaly detection. Choosing a model before understanding the structure of the task inevitably leads to disappointing outcomes.
Despite sharing the same visual domain, image processing, CV, ML, and DL solve fundamentally different problems. One stabilizes raw signals. Another extracts meaning. The third learns statistical structure. And the last uncovers levels of complexity that no handcrafted logic could ever capture. None of these approaches replace the others; they operate as layers of the same system, each indispensable for the right task.
Successful projects don’t start with architectures or trends. They start with clarity:
Teams that ignore these realities often end up overpaying for solutions that are too complicated for their purpose or, conversely, relying on handcrafted logic that collapses the moment real-world noise enters the picture.
The most forward-thinking AI development teams treat visual AI as an ecosystem rather than a ladder. They know that analytical algorithms still excel when data is scarce. They rely on ML when patterns need statistical grounding. They choose DL when scale unlocks deeper structure. And they combine these methods whenever the problem space demands it. That maturity turns methodology into strategy instead of guesswork.
Companies that embrace this perspective avoid the common trap of choosing technology for its novelty. Instead, they select tools for their fitness and in doing so, gain systems that are not only accurate but resilient, cost-effective, and future-ready. For teams looking to build solutions that hold up in real-world conditions, partnering with a custom computer vision development company helps align methods with business value, not fashion. In the long run, that alignment becomes the most powerful differentiator of all.
Choosing the right computer vision approach starts with understanding the task, the data, and real-world constraints. If you’re evaluating a CV initiative or rethinking an existing one, discussing it with experienced engineers can help avoid costly missteps.

In practice, the debate around computer vision vs image processing often comes down to predictability and data availability. Image processing works best when the visual input is consistent and the task can be described through clear mathematical rules, such as noise removal, contrast normalization, or geometric correction. In these cases, analytical algorithms are faster, cheaper, and easier to maintain than learning-based models. CV models become necessary only when the task involves interpretation, ambiguity, or changing visual conditions that cannot be captured through fixed rules.
Discussions framed as image processing vs computer vision sometimes miss the fact that these approaches operate at different levels of the pipeline. Image processing prepares visual data by stabilizing and enhancing it, while computer vision focuses on extracting meaning. Even the most advanced CV models depend on clean, consistent input. Without proper preprocessing, model accuracy degrades, training becomes unstable, and results vary unpredictably in production environments.
The contrast between digital image processing vs computer vision reflects a shift from signal transformation to semantic understanding. Digital image processing applies predefined mathematical operations to pixels, ensuring visual consistency and clarity. Computer vision systems build on that foundation to detect objects, track movement, or interpret scenes. Modern solutions often combine both: analytical processing for stability and learning-based models for interpretation.
Comparisons like NLP vs computer vision vs image processing can be misleading because these fields address entirely different data modalities. Natural language processing works with language structures and context, image processing handles raw visual signals, and computer vision focuses on understanding visual content. Each domain requires distinct pipelines, data preparation strategies, and evaluation metrics. Treating them as interchangeable often leads to flawed system design and unrealistic expectations.
The distinction between computer vision vs machine learning lies in specialization. Machine learning is a broad set of methods for discovering patterns in data, regardless of format. Computer vision applies those methods specifically to visual information, combining ML techniques with domain-specific preprocessing, geometry, and sensor modeling. Effective CV systems rarely rely on ML alone — they integrate multiple layers tailored to how visual data is captured and interpreted.

