










This website uses cookies to help improve your user experience
Video 
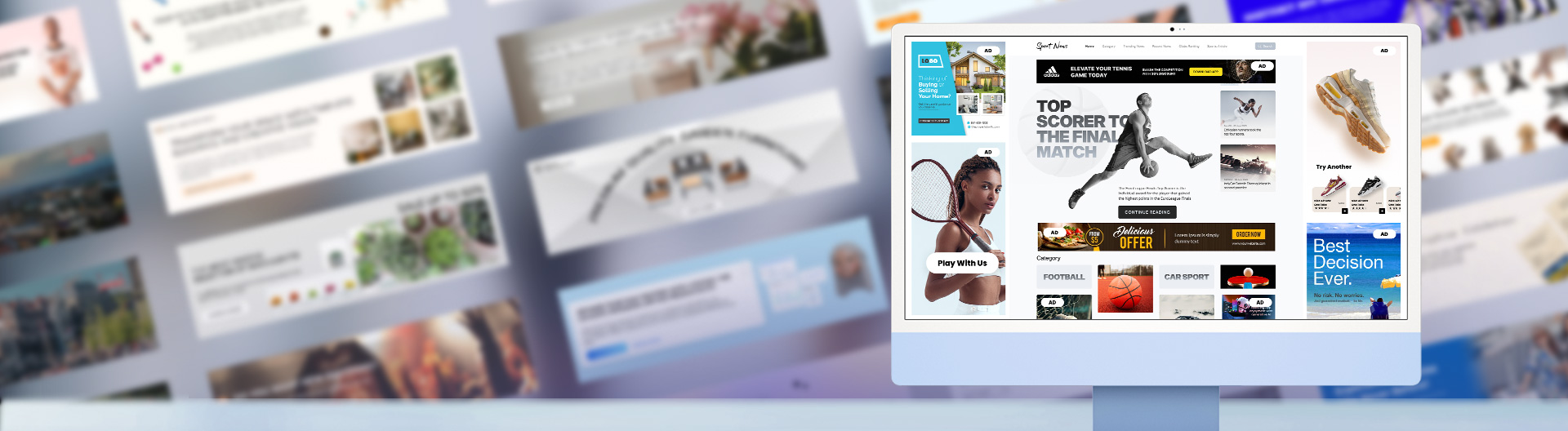
Video streaming
We create video solutions that click with users
About 20 years of delivering technical excellence to the video streaming industry
Learn more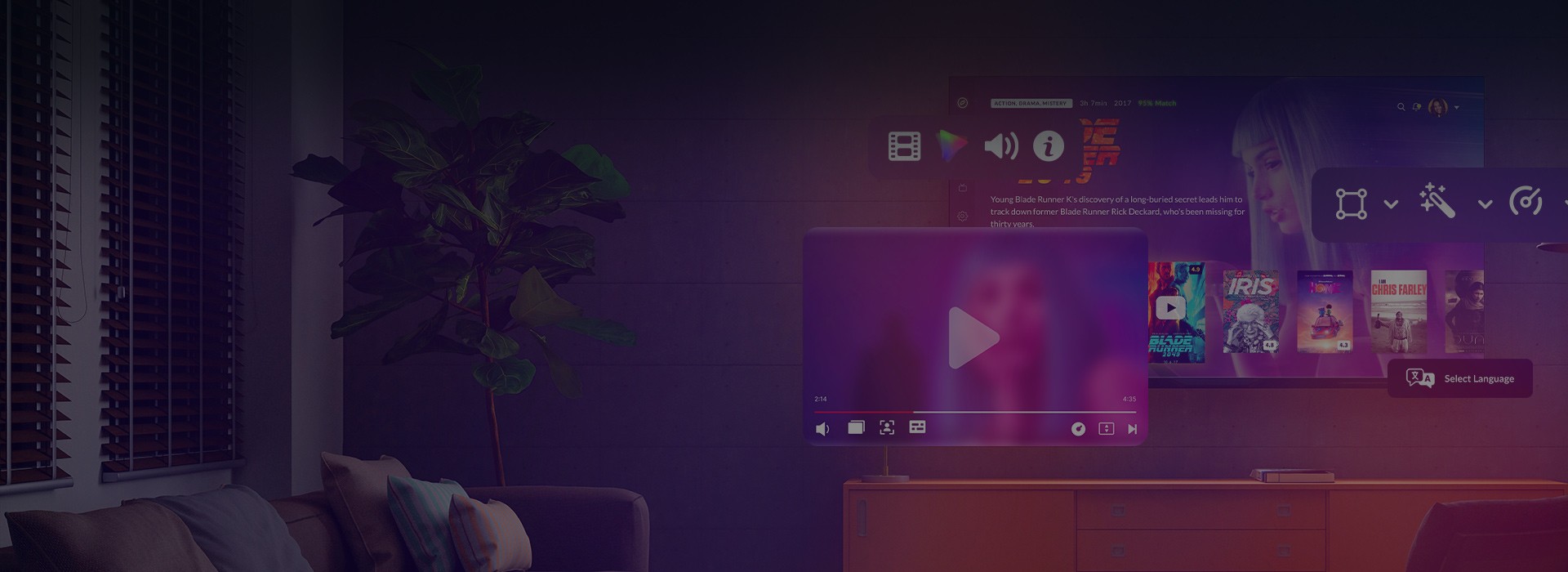
EdTech
EdTech
Delivering custom solutions for EdTech
Our team creates tailored eLearning apps that take on any challenge of the industry
Learn more
AdTech
AdTech
Custom AdTech for intelligent advertising
360-degree AdTech ecosystem knowledge backed by a 12-year experience in the domain
View cases
Data & AI
Data
Turn big data challenges into winning strategies
We have a handful of tech and consulting big data offerings to pave your project road to success
Learn more
Services
Services
Custom software development
We provide full-fledged software development services, from IT consulting and custom software engineering to enterprise-grade integrations and quality assurance
Get a quote Custom Software Solutions Building tailored, domain-specific solutions to unlock business value and ensure a competitive edge Product Development Enabling product ideation, design, growth and distribution across markets Managed Software Engineering Product-minded Agile squads, enterprise-wide program management, digital transformation enablement R&D Applying innovative approaches and ideas at every stage of your software project Quality Assurance Leveraging manual and automated testing capabilities to achieve the highest level of customer satisfaction Scalability of Delivery Scaling and optimizing processes and resources effectively and in line with your needs
Portfolio
Portfolio
450+ clients including Fortune 500 and Forbes 2000 firms
We help global industry leaders, recognized technology innovators, telecoms, content owners, broadcasters, and other clients drive business growth
Explore Projects Company
Company
Continuous value delivery
We enable progressive businesses to transform, scale, and gain competitive advantage with innovative, tailor-made software
Get a quote